Основы статистического вывода
Код занятия на Python
https://colab.research.google.com/drive/1Of-RYLXdmM4Z_1PqRAZ85980FYjAbxrc?usp=sharing
Выборка
Выборка - часть генеральной совокупности
Выборочные статистики нельзя напрямую интерпретировать как характеристики генеральной совокупности.
Метрики центральных тенденций
среднее: mean()
медиана: median()
мода (table() и другие методы оценки частот)
Например, выберем случайным образом 20 чисел из ряда от 1 до 100, и посчитаем метрики центральных тенденций ряда.
Надо помнить, что среднее менее устойчиво к отклонениям от нормального распределения, поэтому сравнение среднего и медианы может быть полезно для понимания данных, а медиана в целом более устойчивая к выбросам оценка.
Метрики разброса
размах: range()
дисперсия: var()
стандартное отклонение (\(\sigma\)): sd()
## [1] 4 93## [1] 1031.671## [1] 32.11964Обычно используют размах и стандартное отклонение. Стандартное отклонение понятнее дисперсии, потому что в тех же единицах, что и измерение, поэтому можно сказать \(\overline{x} \pm \sigma\). В целом, стандартное отклонение служит метрикой “точности измерения” - чем выше дисперсия, тем менее точное измерение. Для большинства процессов характерно увеличение точности (снижение дисперсии) измерения с увеличением выборки - чем больше выборка, тем меньше дисперсия. Однако это правило неприменимо, в частности, к равномерному распределению и некоторым другим ситуациям (процессам с бесконечной дисперсией).
Нормальное распределение
Нормальным называется распределение вероятностей, которое для одномерного случая задаётся функцией Гаусса.
Нормальное распределение играет важнейшую роль во многих областях знаний. Случайная величина подчиняется нормальному закону распределения, когда она подвержена влиянию большого числа случайных факторов, что является типичной ситуацией в анализе данных. Поэтому нормальное распределение служит хорошей моделью для многих реальных процессов.
Основные функции для работы с распределениями:
d*() — функция вероятности (probability mass function) для дискретных распределений и функция плотности вероятности для непрерывных распределений. В практике аналитиков используется редко, нужна для понимания и визуализации теоретической формы распределения при разных параметрах.
p*() — функция накопленной плотности распределения (cumulative distribution function; cdf), позволяет получить накопленную вероятность получить такое значение при условии, что оно принадлежит указанному распределению. Другими словами, с помощью этой функции можно получить вероятность получить такое значение или меньшее. Например, мы знаем, что в популяции средний мужчин распределен приблизительно нормально, со средним ростом \(\overline{M}\) = 170 и \(\sigma\) = 10. Попробуем понять, какова будет вероятность встретить человека с ростом 180 см или выше:
## [1] 0.8413447Мы получаем значение 0.8413 - так как pnorm() использует функцию накопленной плотности, то это вероятность получить значение меньше 180 (то есть, 84% встреченных людей будет ниже 180 см.). Для того, чтобы оценить вероятность встретить значения больше, чем указанное (в нашем примере — встретить человека выше 180 см.) необходимо либо вычесть из единицы, либо воспользоваться аргументом lower.tail:
## [1] 0.1586553## [1] 0.1586553- q*() — квантильная функция (quantile function) или обратная функция накопленной плотности распределения (inverse cumulative distribution function), позволяет получить значение исходя из квантиля накопленной плотности распределения. Таким образом, если следовать примеру с ростом людей в популяции, мы можем оценить, какова будет вероятность встретить людей из, допустим, верхнего квартиля (с какого роста можно говорить, что этот человек входит 25% самых высоких людей популяции):
## [1] 176.7449Таким образом, если встреченный человек выше 176.74 см., то он выше чем 3/4 всех людей популяции.
- r*() — используется для генерации семплов из распределения определенной формы и с заданными параметрами. Например, генерируем семпл из нормального распределения:
# генерируем данные сразу из стандартного нормального распределения
x <- rnorm(1000, mean = 0, sd = 1)
x[1:10]## [1] 0.9594941 -0.1102855 -0.5110095 -0.9111954 -0.8371717 2.4158352
## [7] 0.1340882 -0.4906859 -0.4405479 0.4595894C помощью rnorm() делаются выборки из распределения с заданными параметрами, однако чем меньше выборка, тем сильнее эмпирические значения среднего и стандартного отклонения будут отличаться от заданных при генерации:
## [1] -0.02189492## [1] 0.9992201Префиксы p, r, d, q используются не только для нормального распределения (-norm()), в частности, для t-распределения, логнормального (-lnorm), равномерного (-unif) и т. д.
Z-преобразование
Преобразование (его иногда называют нормализацией), которое приводит нормально распределенные данные с произвольным средним и стандартным отклонением к стандартному нормальному распределению с \(\overline{M}\) = 0 и \(\sigma\) = 1:
\[z = \frac{X_i-\overline{M}}{\sigma}\]
## [,1]
## [1,] -1.4863011
## [2,] -1.1560120
## [3,] -0.8257228
## [4,] -0.4954337
## [5,] -0.1651446
## [6,] 0.1651446
## [7,] 0.4954337
## [8,] 0.8257228
## [9,] 1.1560120
## [10,] 1.4863011
## attr(,"scaled:center")
## [1] 5.5
## attr(,"scaled:scale")
## [1] 3.02765Нормализация данных нужна в ситуациях, когда надо сравнивать выборки и распределений с разными параметрами или когда надо все измерения привести к одному масштабу. Допустим, у нас есть две выборки. Сравнивать распределение данных между выборками достаточно сложно, поэтому обычно сначала нормализуют, а потом сравнивают. Точно также нормализовать данные необходимо в некоторых алгоритмах типа кластерного анализа, чтобы масштаб измерения не вносил дополнительные эффекты.
Проверка гипотез. NHST
В классической статистике проверяется гипотеза, что группы не различаются (что разница средних равна нулю с высокой вероятностью, как в t-тесте). Концепция p-value исходит из этих условий — оценивается, насколько вероятно получить такое значение или большие различия. И если вероятность невысока (обычно за порог берется 5%, 0.05), то делается вывод, что вероятность нулевой разницы групп низкая и можно считать, что группы различаются.
\(H_0: \overline{M_1} = \overline{M_2}\)
Если формально, то p-value:— вероятность получить такие или более экстремальные значения при условии, что \(H_0\) истинна.
Тестовые статистики и распределения
Все критерии сравнения групп — это поиск какой-то метрики, по которой можно оценить степень различия. Это может быть как разница средних, так и соотношение групповой и межгрупповой дисперсий, и степень отклонения наблюдаемой вероятности от ожидаемой, и прочие метрики. Притом эти значения различия могут быть описаны разными (каждое своим) теоретическими распределениями:
t, t-test, t.test(): сравнение средних значений групп
F, ANOVA: сравнение внутригрупповой и межгрупповой дисперсий
\(\chi^2\), ci-square test, prop.test(): сравнение вероятностей в дискретных (биномиальном) распределениях
В критериях вычисляется эта разница и нормируется на совокупную дисперсию групп (своеобразное z-преобразование), и потом вычисляется вероятность получить такую разницу (p-value).
Допустим, у нас есть две группы: мужчины (\(\overline{M}\) = 175, \(\sigma\) = 10) и женщины (\(\overline{M}\) = 165, \(\sigma\) = 10):
Мы хотим понять, значимо ли это различие между двумя группами или нет. Для этого мы формулируем нулевую гипотезу, которую и проверяем статистическими критериями: нулевая гипотеза всегда о том, что различий между группами нет. Мы никогда не можем принять гипотезу (потому что мы имеем дело с выборками, мало ли что попадется в других выборках), мы можем только найти существенные аргументы, чтобы ее отвергнуть.
Таким аргументом будет оценка вероятность получить такое различие между группами, какое мы наблюдаем на наших выборках, при предположении, что различий нет (равны нулю). То есть мы обращаемся к теоретическому распределению меры различий, в котором математическое ожидание (среднее для нормального распределения) равно нулю и на этом распределении оцениваем, какова вероятность получить то значение, которое мы получили на наших выборках.
Один из самый простых тестов для сравнения групп — критерий Стьюдента, он же t-тест. В этом тесте высчитывается тестовая статистика t — взвешенная на несмещенную оценку дисперсии разница средних двух групп (в нашем случае предполагается равенство дисперсий).
Критерий t имеет свое собственное распределение, которое при больших значениях выборок приближается к нормальному. Если посмотреть на тело функции t.test(), то там видно, как используется t-распределение (tstat и df — вычисляемое значение t и степень свободы):
pval <- 2 * pt(-abs(tstat), df)
alpha <- 1 - conf.level
cint <- qt(1 - alpha/2, df)
cint <- tstat + c(-cint, cint)Соответственно, для проверки нулевой гипотезы с помощью t-критерия мы должны высчитать эмпирическое значение критерия t на наших данных и оценить, насколько вероятно получить такое или еще большее значение при условии, что наиболее вероятное значение (математическое ожидание) равно нулю.
##
## Two Sample t-test
##
## data: x_m and x_f
## t = 2.0425, df = 48, p-value = 0.04661
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## 0.08088702 10.27932238
## sample estimates:
## mean of x mean of y
## 171.1373 165.9572(alternative = “two.sided”, так предполагаем, что среднее группы x_f может быть больше среднего группы x_m, так и наоборот, x_f может быть больше группы x_m — то есть, мы должны учесть, что наше эмпирическое значение разницы между группами может быть как больше нуля, так и меньше нуля, в обоих хвостах распределения).
В выводе функции мы видим значение t и оценку p-value. Перепроверим самостоятельно (df считается как n1 + n2 - 2, где n1 и n2 — численность первой и второй выборок, а 2 — количество выборок):
## [1] 0.000353164(на 2 умножаем, потому что смотрим оба хвоста распределения).
Bootstrap
Техника “размножения выборки”. Если считать, что собранная выборка репрезентативна относительно ген.совокупности, то ресемплы из этой выборки так же будут в какой-то мере репрезентативны. Соответственно, если сделать множество ресемплов (в том числе и с возвращениями) и в каждом ресемпле считать какую-нибудь статистику, например, среднее - то можно получить распределение среднего значения. И это распределение будет вполне отражать ген.совокупность. Соответственно, можно таким образом численно определить границы доверительного интервала среднего.
Техника хороша тем, что устойчива к форме распределения данных, и не опирается на них. Во-вторых, очень полезна для работы с малыми выборками и мета-анализами. Техники бутстрепа разные, от выкидывания по очереди элемента (jacknife) до перевыборки или перемешивания (используется для сравнения групп):
jacknife
resample
permutation
Перестановочные тесты
Логическое продолжение парадигмы бутстрепа - если ресемплить не какую-то стат.метрику (типа t или F), а разницу между группами. При этом проверяется не просто разница между двумя семплами, а насколько вероятно вообще такое разбиение - грубо говоря, множество раз группы перемешиваются и переразбиваются, и в каждом новом разбиении считается различие (различие средних, нередко просто больше или меньше). В результате получается выборка значений различия, и потом оценивается, насколько вероятно было получить то разбиение, которое было исходно в эксперименте.

Таким образом вместо принятия решения о нулевой гипотезе на основе теоретических распределений, решение принимается на основе эмпирического распределения - это позволяет сравнивать группы, наблюдения в которых распределены отличным от нормального образом.
Перестановочные тесты в R
При желании можно написать свою реализацию но чаще используют пакет coin, в частности функцию oneway_test().
## Loading required package: survival# собираем табличку, чтобы была группирующая переменная
x_dt <- data.table(
group = factor(rep(c('male', 'female'), each = 25)),
height = c(x_m, x_f)
)
# Fisher-Pitman permutation test
oneway_test(height ~ group, data = x_dt, distribution = approximate(nresample = 10000))##
## Approximative Two-Sample Fisher-Pitman Permutation Test
##
## data: height by group (female, male)
## Z = -1.9795, p-value = 0.0448
## alternative hypothesis: true mu is not equal to 0Критерий согласия \(\chi^2\)-Пирсона
Продуктовые аналитики чаще всего имеют дело с биномиальными данными - уровнем конверсии, уровнем удержания и т.д. То есть с теми процессами, где есть какая-то доля успешных и неуспешных исходов.
Для проверки гипотез о различии групп по доле успешных событий используется обычно \(\chi^2-критерий Пирсона\), он же критерий согласия. Основная идея - оценить разницу в вероятности полученной доли успешных событий и ожидаемой доли, это делается для каждого из исходов. Нормированная сумма квадратов этих разниц и составляет значение \(\chi^2\), по теоретическому распределению которого и определяется p-value:
\[\chi^2_n = \sum_{i=1}^n{\frac{(O_i - E_i)^2}{E_i}}\]
Классический пример - есть монетка, ее подбросили 60 раз. 20 раз выпал орел и 40 раз выпала решка. Насколько случайно такое соотноешние, может ли быть так, что одна из сторон монетки искусственно утяжелена? В R д
я ответа на этот вопрос можно воспользоваться функцией prop.test() (в который по умолчанию включается поправка Йетса на непрерывность). Ожидаемые вероятности для монетки с равными сторонами будут 30 раз орел и 30 раз решка, поровну. Укажем вектор с количеством наблюдаемых исходов и вектор с количеством испытаний:
##
## 2-sample test for equality of proportions with continuity correction
##
## data: c(20, 30) out of c(60, 60)
## X-squared = 2.7771, df = 1, p-value = 0.09562
## alternative hypothesis: two.sided
## 95 percent confidence interval:
## -0.35721175 0.02387842
## sample estimates:
## prop 1 prop 2
## 0.3333333 0.5000000Как мы видим, вероятность получить 20 (или еще меньше) выпадений орлов при 60 подбрасываниях составляет около 9.5%. Это не очень много, но все равно больше конвенционального порога в 5% (p-value = 0.05), поэтому мы можем сделать вывод, что получить 20 орлов при 60 случайных подбрасываниях маловероятно, но все же вполне возможно. То есть, соотношение 20/40, полученное в эксперименте незначимо отличается от случайного (30/30), и монетка сбалансирована корректно.
Размеры эффекта
В какой-то момент пришли к идее, что просто сравнивать группы на значимость различий недостаточно - хорошо бы понимать, как сильно различаются группы. Из этого выросло целое направление, power analysis, где в фокусе анализа размеры эффектов и их взаимосвязь с размером выборки, а так же ошибками первого и второго рода.
Индексов размера эффекта много - и для непрерывных переменных, и для дискретных, и для оценки взаимосвязи. В том числе существуют индексы для сложных моделей, таких как дисперсионный анализ с взаимодействием факторов и т.д. Обычно из одного индекса некоторыми преобразованиями можно получить другой индекс.
Ошибка II рода
Когда мы говорим о нулевой гипотезе, мы предполагаем, что различий между группами нет. Соответственно, мы оцениваем теоретическую вероятность (p-value) получить такое или более экстремальное значение, как в нашем эксперименте. Для этого мы вычисляем разницу между группами и смотрим по кривой распределения этой метрики различия, какая вероятность получить такое значение или больше/меньше (в зависимости о того, левый или правый край распределения мы берем во внимание).
При этом есть расширение этого подхода — когда мы отвергаем нулевую гипотезу (говорим, что маловероятно получить наше эмпирическое значение при предположении, что группы не различаются), мы утверждаем, что разница между группами принадлежит тому же по форме распределению, но с другими параметрами. На примере нормального распределения (и z-критерия) это будет означать, что наше эмпирическое значение разницы принадлежит не распределению с mean = 0, а распределению с ненулевым средним (т. е. смещенным по оси OX вправо).
Таким образом мы приходим к тому, что мы можем оценить, какова вероятность получить такое значение, если группы не различаются (ошибка I рода, она же ошибка ложного срабатывания, когда мы утверждаем, что различие есть, когда его на самом деле нет). И мы можем оценить, какова вероятность, что это значение на самом деле принадлежит распределению параметра, описывающему ситуацию, когда группы действительно различаются. Эту вероятность называют мощностью теста (\(\beta\)), \(1 - \beta\) — ошибка II рода (вероятность пропуска, когда мы утверждаем, что различия нет, а на самом деле оно есть).
Ошибки I и II рода хорошо иллюстрирует вот такая картинка:

Оценка выборки
Все четыре ключевых термина: размер выборки, размер эффекта, ошибка I рода и ошибка II рода (мощность теста) тесно взаимосвязаны между собой. По сути зная три из них, можно оценить четвертую. Так, размер выборки влияет на форму распределения метрики разницы групп (насколько длинные и тонкие хвосты); размер эффекта — на величину сдвига по оси OX распределения метрики, описывающей ситуацию, когда группы не различаются); ошибка I рода — какую, условно, часть хвоста распределения мы считаем маловероятные значения при нулевом различии групп; ошибка II рода — насколько сильно пересекаются наш хвост из распределения отсутствии различия и распределение при предположении, что группы правда различаются.
Есть очень хорошее приложение, которое визуализирует эту связь (картинка кликабельна):
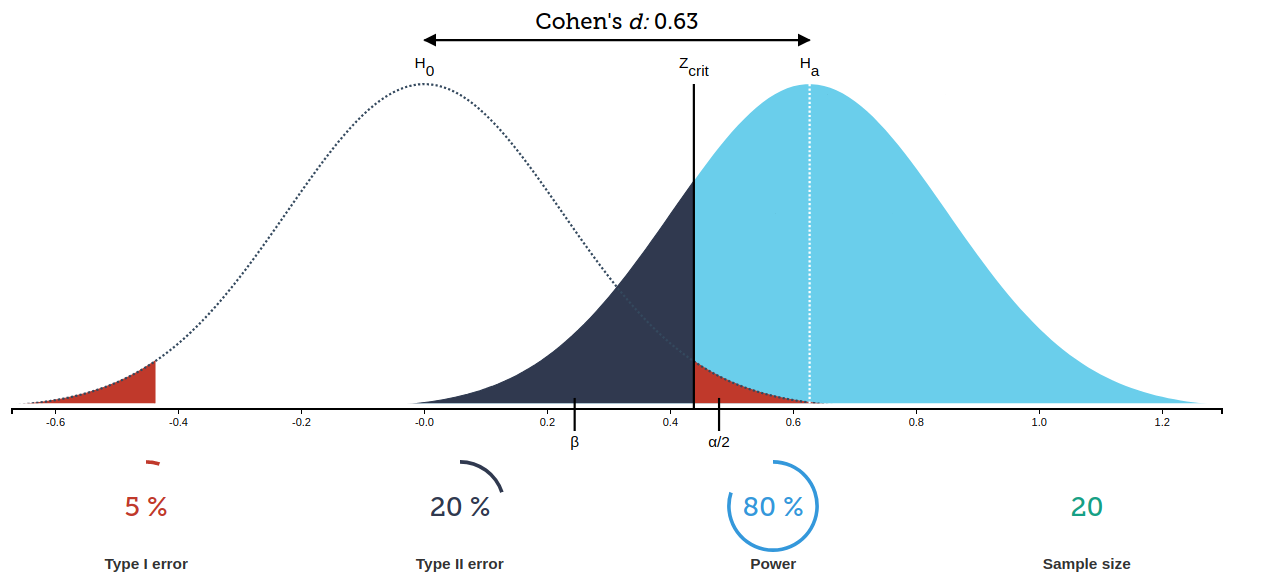
power.prop.test()
Для оценки мощности теста и для оценки выборки исходя из заданных условий (размеры ошибок I и II рода, ожидаемого размера эффекта) есть достаточно много инструментов и алгоритмов. Один из весьма популярных — G*Power. При этом стоит учитывать, что чем сложнее дизайн эксперимента (многофакторные влияния, внутри- и межгрупповые планы, наличие случайных эффектов и т. д.), тем сложнее для выведения и, соответственно, сомнительнее оценки мощности теста и расчеты выборки.
В R для анализа мощности или оценки выборки для теста пропорций (именно этим тестом мы обычно проверяем значимость в различии конверсии или удержания) можно воспользоваться функцией power.prop.test(). Функция принимает на вход размер каждой группы (предполагается, что группы одинаковы), доля успешных событий для первой группы, доля успешных событий для второй группы, уровень значимости и мощность теста.
В том случае, если в какой-то из этих аргументов выставить NULL, то в результатах теста будет предложено необходимое значение. То есть, зная наблюдаемую вероятность события в двух группах, а так же имея требования к точности эксперимента (ур.значимости и мощность, ошибки I и II рода) можно вычислить необходимую выборку. Или, например, имея выборку, вероятность события в одной группе и требования к уровням ошибок I и II рода, можно оценить какую значимую разницу можно почувствовать на этой выборке.
Аргументы функции:
## function (n = NULL, p1 = NULL, p2 = NULL, sig.level = 0.05, power = NULL,
## alternative = c("two.sided", "one.sided"), strict = FALSE,
## tol = .Machine$double.eps^0.25)
## NULLПростейший пример, у нас есть удержание пользователей на уровне 35%, мы хотим протестировать новый функционал, который, по нашим ожиданиям, повысит удержание на 2%. Сколько необходимо пользователей, с учетом стандартных требований к точности и мощности теста (ошибка первого рода - 5%, ошибка второго рода - 20%).
Воспользуемся функцией power.prop.test()и прямо укажем, что нам неизвестна выборка:
##
## Two-sample comparison of proportions power calculation
##
## n = 9040.73
## p1 = 0.35
## p2 = 0.37
## sig.level = 0.05
## power = 0.8
## alternative = two.sided
##
## NOTE: n is number in *each* groupКак мы видим, нам необходимо не менее 9 тысяч пользователей в каждой группе аб-теста - в таком случае мы можем утверждать, что различия в удержании между группами в 2% и выше неслучайны.
Если же мы попробуем задать количество пользователей каждой группы (например, у нас мало денег и мы не можем привлечь много пользователей), среди которых мы ожидаем получить значимое различие в 2% (при том же уровне ошибки первого рода в 5%), то у нас резко упадет мощность. Это значит, что велика будет вероятность на такой выборке пропустить эффект и сказать, что различия нет, хотя оно на самом деле есть:
##
## Two-sample comparison of proportions power calculation
##
## n = 1000
## p1 = 0.35
## p2 = 0.37
## sig.level = 0.05
## power = 0.1518592
## alternative = two.sided
##
## NOTE: n is number in *each* groupОбычно оценку мощности и расчет выборки делают до эксперимента, так как после эксперимента оценивать ошибку II рода несколько бессмысленно, эксперимент-то уже проведен. Максимум можно оценить вероятность ошибки второго рода (насколкьо могли пропустить эффект) и переделать.
Практикум
Задание из тестового задания на продуктового аналитика в Альфа-банк.
Был проведен эксперимент: изменение заголовка на кнопке на главном экране подписной страницы. Сделан акцент на выгоде пользователя.
Описание полей:
- date – Дата
- deviceCategory – Тип устройства
- sourceMedium – Источник и канал привлечения
- experimentVariant – Группа (варианта) эксперимента: 0 - контроль, 1 - тест
- clickButtonOnMain – Кликнул/не кликнул по кнопке на главной странице в рамках сеанса (1 – кликнул, или 0 – не кликнул)
- sessionDuration – Время проведенное на сайте в рамках сеанса
Данные: AB_ab_2_1
Проверьте гипотезы:
- Есть ли значимое изменение в большую или меньшую сторону у клика на целевую кнопку?
- Изменилось ли время проведенное на сайте в рамках сеанса?
- Напишите, какими тестами пользовались и почему выбрали их?
- Напишите выводы, которые можно сделать на основе анализа.
Импортируем датасет и приводим к нормальному виду:
library(data.table)
dataset <- fread('https://raw.githubusercontent.com/upravitelev/mar231f/refs/heads/main/data/AB_ab_2_1.csv')
dataset[, sessionDuration := gsub(',', '.', sessionDuration, fixed = TRUE)]
dataset[, sessionDuration := as.numeric(sessionDuration)]Считаем количество нажавших на кнопку в каждой группе и количество всего пользователей:
dataset_stat <- dataset[, list(n_users = uniqueN(userId)), keyby = list(experimentVariant, clickButtonOnMain)]
dataset_stat[, total_users := sum(n_users), keyby = experimentVariant]
dataset_stat## Key: <experimentVariant>
## experimentVariant clickButtonOnMain n_users total_users
## <int> <int> <int> <int>
## 1: 0 0 1293 1485
## 2: 0 1 192 1485
## 3: 1 0 1325 1458
## 4: 1 1 133 1458Применяем тест пропорций, видим значимые различия (т.е. кнопка повлияло на количество кликов):
##
## 2-sample test for equality of proportions without continuity correction
##
## data: c(133, 192) out of c(1485, 1458)
## X-squared = 13.289, df = 1, p-value = 0.0002669
## alternative hypothesis: two.sided
## 95 percent confidence interval:
## -0.0647569 -0.0194930
## sample estimates:
## prop 1 prop 2
## 0.08956229 0.13168724Считаем значимость различий между группами по длительности сессий:
##
## Welch Two Sample t-test
##
## data: sessionDuration by experimentVariant
## t = -45.299, df = 2217.4, p-value < 2.2e-16
## alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
## 95 percent confidence interval:
## -13.58488 -12.45749
## sample estimates:
## mean in group 0 mean in group 1
## 120.0380 133.0592Полезные ссылки
Глава из учебника по R и статистике моего коллеги по психфаку Ивана Позднякова
Онлайн-курс Толи Карпова по основам статистики. Один из самыйх известных русскоязычных онлайн-курсов. В целом довольно неплох, рекомендую обратить внимание на первые пару блоков (введение и сравнение средних).
Расчет критерия \(\chi^2\) вручную. Очень хорошо описана логика расчета.
Еще один хороший пример расчета. Неплохо описана идея степеней свободы и формы распределения.
Один из лучших учебников по размерам эффекта. По ссылке только название и ссылка на амазон, но при желании файл можно найти в сети.